Open Source
I view building software in the open as a mode of creative exploration. It lets me quickly act on inspiration, delve into new topics, and make tools that improve people's lives.
You'll see that I particularly like programming languages, distributed systems, machine learning, computer graphics, music, and art.
If you find something interesting, let me know!
Table of Contents
Feature Selection in High Dimensional RNA Sequencing Data December 2023
Classification of cancer types from RNA sequencing data using feature selection methods.
Precise classification of cancer types is a central problem for cancer therapy and diagnosis. In recent years, there has been an increasing interest in high-accuracy tumor classification based on RNA sequencing data. In this project, we follow the methodology of Mohammed et al. [2021] in classifying tumor types from among the most diagnosed cancer types among women (breast, lung, colorectal, thyroid, and ovarian) but test a greater diversity of gene selection methods. Our highest accuracy methods yield better-performing test set accuracy on held-out data than the original paper. Thus, our proposed methods can aid in the detection and diagnosis of cancer in women and consequently aid in early treatment to improve survival.
Links: GitHub
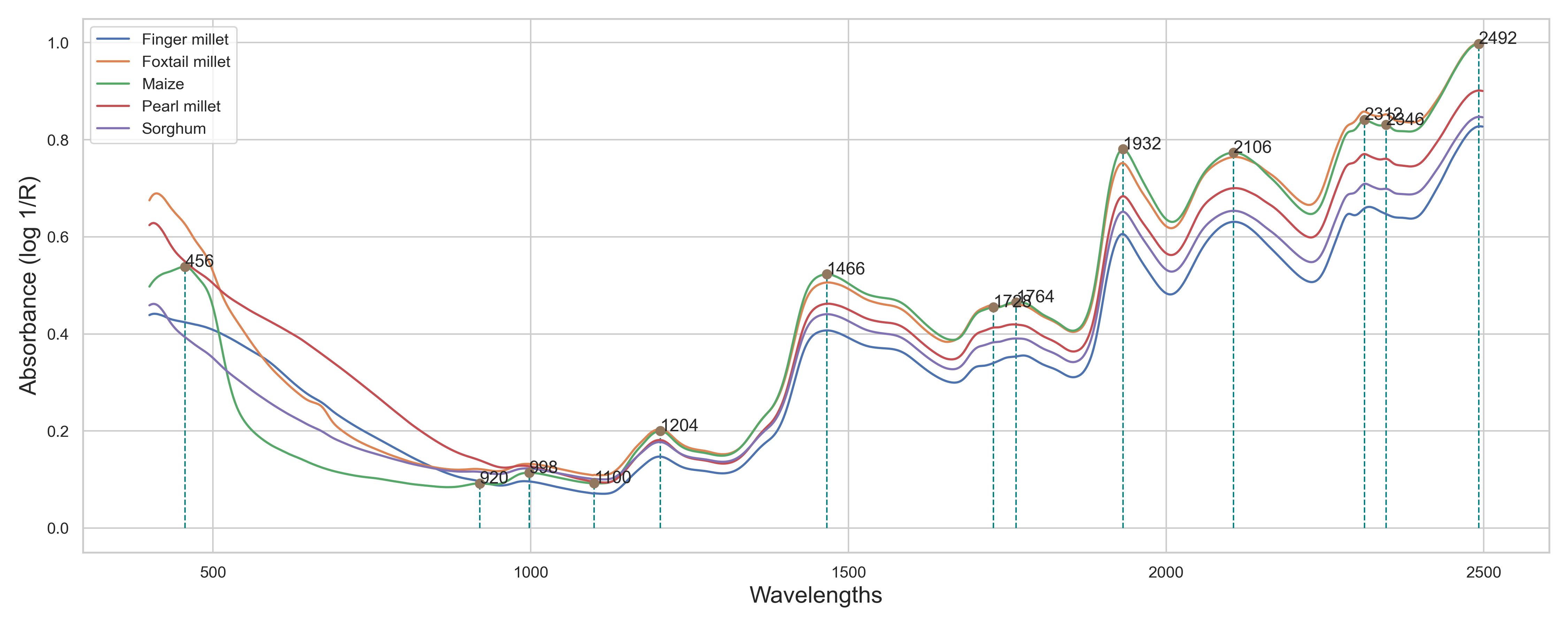
Protein Palette December 2022
Determining the protein content from multiple grains using near-infrared spectroscopy, statistical modeling and deep learning algorithms.
Conducted protein content analysis in various chemicals using predictive analysis and spectroscopy techniques. Assembled a dataset of 1000+ bands using mobile and benchmark sensors to measure spectroscopic absorbance. Applied Multiplicative Scatter correction and Standard Normal Variate (SNV) correction to preprocess the data. Utilized convolution and Savitzky-Golay filtering to remove linear trends and smooth the data for further analysis. Developed a deep belief statistical model, achieving an R2 value of 0.91 with just 300 wetlab samples.
Links: GitHub
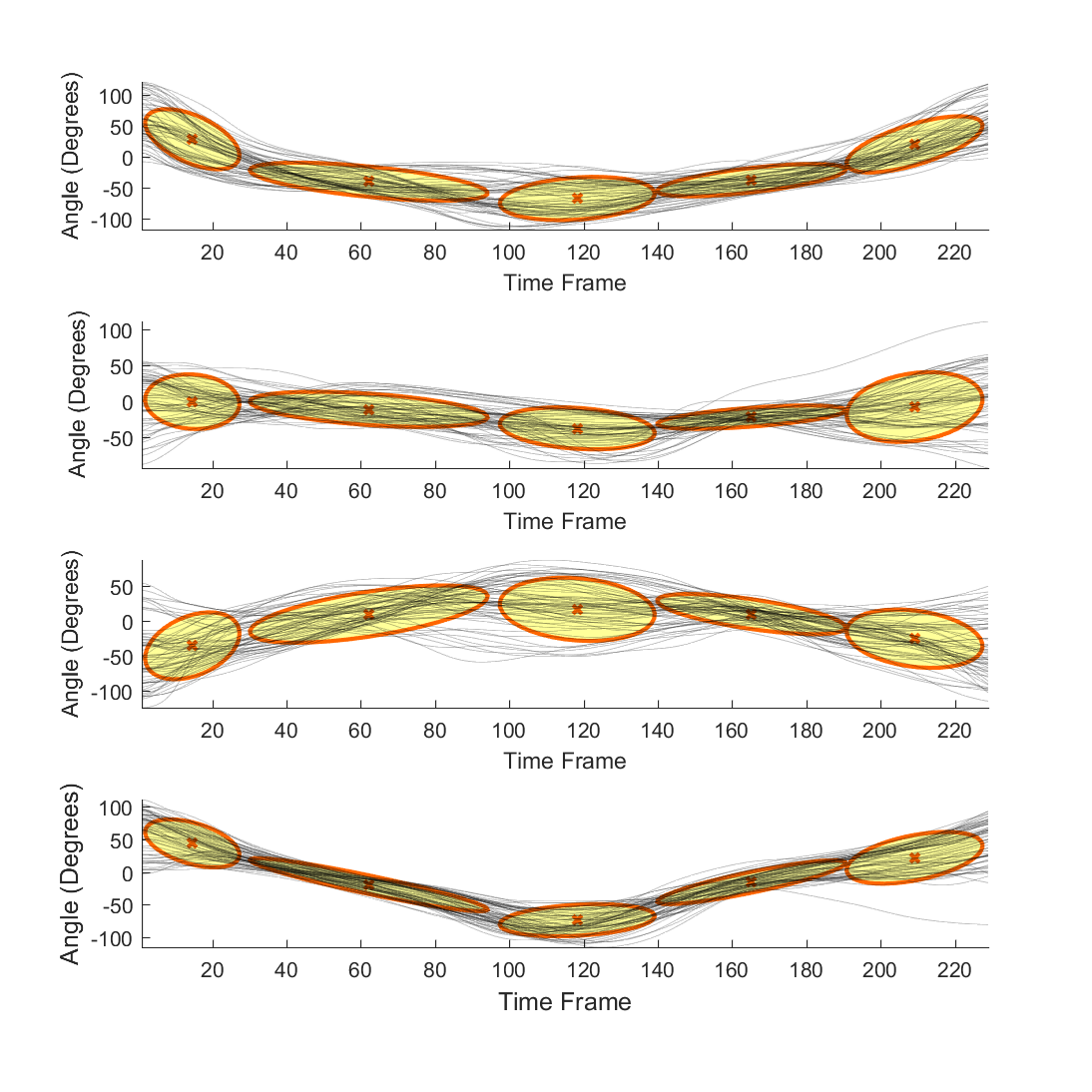
Dimensionality Reduction for NIR Images November 2022
Dimensionality reduction and predictive analysis from very sparse data.
Developed t-SNE and Uniform Manifold Approximation and Projection models with tuned perplexity hyperparameter for dimensionality reduction and predictive analysis from very sparse data. Formulated and authored a novel architecture employing autoencoders to project high dimensional data from the NIR images into a low dimensional manifold. Implemented a Gaussian Mixture Model (GMM) to derive a parametric probabilistic model which was deployed to evaluate the consistency in unseen dynamics.
Links: GitHub
TextQuraton August 2022
Invoice text curation from images.
Designed, implemented and pitched TextQuraton, a handwriting curating application for parsing medical bills and using the data to identify fraudulent bills. Implemented a modified DistilBert based classifier coupled with context module and n-grammar alongside attention module. Developed spatial transformers alongside a CRNN and bidirectional-LSTM module to parse handwritten bills taking into consideration the augmented images. Achieved an accuracy of 93.67% averaged over all the extracted tags.
Links: GitHub

TrueUpvotes July 2022
Predicting Reddit post upvotes using a modified DistilBert model.
Scraped over 1 million posts from various subreddits using the Reddit API to create a dataset for predicting the number of upvotes based on various metrics and the structure of the posts. Conducted univariate analysis and treated outliers and missing values to explore the data and identify potential factors affecting collinearity in the dataset. Applied cluster algorithms (k-means and hierarchical clustering) to identify the most upvoted genres. Implemented a modified DistilBert model with a context module, n-grammar, and attention module to summarize, extract relationships, perform named entity recognition, and extract keywords from the collected dataset corpus. The proposed architecture achieved an accuracy of 96.8% in predicting the upvote category. Designed, implemented and pitched TextQuraton, a handwriting curating application for parsing medical bills and using the data to identify fraudulent bills. Implemented a modified DistilBert based classifier coupled with context module and n-grammar alongside attention module. Developed spatial transformers alongside a CRNN and bidirectional-LSTM module to parse handwritten bills taking into consideration the augmented images. Achieved an accuracy of 93.67% averaged over all the extracted tags.
Links: GitHub

StockSeer June 2022
Tool to analyze stock data.
Created a tool to retrieve and analyze stock data using the Yahoo Finance API and yfinance package. Conducted fundamental and regression analysis, including univariate and multivariate regression using exploratory variables such as Walmart’s rate of return, S&P 500 return, and the US Dollar Index, and a response variable of the company’s rate of return. Performed ROI (rate on investment) analysis and correlation analysis to evaluate global stock market performance. Implemented an EMA10 (Exponential Moving Average 10 days) indicator for predictive modeling and forecasting.
Links: GitHub
Revels November 2021
Website for the annual cultural fest of MIT Manipal.
Part of System and Web Administration} team responsible for designing and implementing the main website for the annual cultural fest of MIT Manipal, responsible for display of events, registration, ticket sales and was accessed by 5000+ users.

Age of Coders (Web Application) August 2020
Web application for an online coding contest with over 150 teams from colleges across India.
Spearheaded a team of 6 students(3 developers, 2 designers and 1 question setter) to develop a web application for an online coding contest that had participation of over 150 teams from colleges across India. Implemented an algorithm which used the data collected during the tournament to award extra points to people with the most points in a region, similar to capture the flag and also didn’t allow more than three submissions for a question. Coordinated project goals, aligned deadlines, defined the UX, designed the features and developed the application. Developed the application using SQL, HTML, CSS , JavaScript, NodeJS and hosted it using AWS.

Greavify April 2019
An application to address grievances logged by college students as a part of Smart India Hackathon.
Designed and implemented an application to address grievances logged by college students as a part of Smart India Hackathon. The application generated appropriate responses and classified grievances using a sentiment analysis model trained and tested on a twitter data-set with a moderately high accuracy. Created a word2vec model which is fed into an embedding matrix, alongside a neural network layer and used a bidirectional LSTM layer to improve accuracy. Visualized the data and presented it using Power BI.
